Characteristic
- 支持容错机制的研究
- 可以计算系统的总花费
- 支持目前广泛接受的工作流的基本特征及其调度算法
- 不仅支持调度算法的评估,而且考虑了不同任务调度/执行的费用和失败情况
- 聚类的策略是静态的,并且没有考虑动态资源的特点
- 不考虑来自不同网格中间件服务的中间件开销
Models and Features
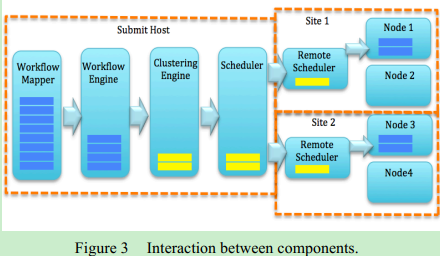
Components
Workflow Mapper: Model workflows as DAGs.
用于导入以XML格式化的DAG文件和其他元数据信息,如文件大小等等,并且在mapping之后,创建一系列tasks并将这些安排到执行环节
Clustering Engine:Merge tasks into jobs so as to reduce the scheduling overheads
Workflow Engine: Manages jobs based on their dependencies to assure that a job may only be released when all of its parent jobs have completed successfully
Workflow Scheduler and Job Execution:
Workflow Scheduler is used to match jobs to worker nodes based on the criteria selected by user.
Support dynamic workflow algorithms:dynamic algorithms, jobs are matched to a worker node in the remote scheduler whenever a worker node becomes idle
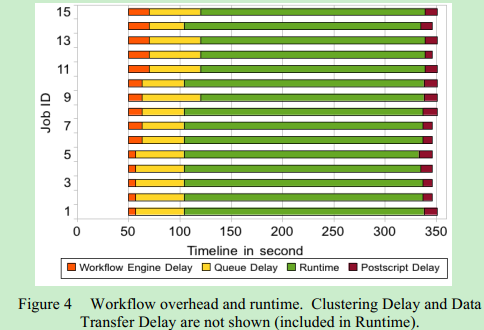
Layered Overhead
Classify workflow overheads into five categories.
Workflow Engine Delay: 度量作业的最后一个父作业完成时间与作业提交到本地队列的时间之间的时间。
Queue Delay:工作流引擎向本地队列提交作业与本地调度程序看到作业运行的时间之间的时间
Postscript Delay and Prescript Delay:在执行作业之前和之后在某些执行系统下执行轻量级脚本所花费的时间。
Data Transfer Delay: 数据在结点之间传输所需要的时间,包含三种过程: staging data in, cleaning up, staging data out.
Clustering Delay:实际任务运行时总和与工作流计划程序看到的作业运行时之间的差异。
Layered Failures and Job Retry
Divide transient failures into two categories: task failure and job failure
Two components to simulate:
Failure Generator: inject task/job failures at each execution site.
故障生成器根据用户指定的分布和平均故障率随机生成任务/作业故障。
Failure Monitor: 收集失败记录(例如,资源ID,作业ID,任务ID)并将它们返回到工作流管理系统,以便它可以动态调整调度策略
Functionality is added to the Workflow Scheduler, which checks the status of a job and takes action based on the strategies that a user selects.
Reclustering is a technique that we have proposed that attempts to adjust the task clustering strategy based on the detected failure rate
