本文将从动力学系统角度去理解深度神经网络。
Neural ODE
Euler method:
ResNet
不同之处在于 : ResNet每一步都有不同的参数,而常微分方程参数是共享的
Memory Cost: O(1), 并且是可逆的
类似于ResNet的连接方式
定义Loss Function:
当使用Euler Method 去解决$\frac{dh(t)}{dt} = NNetwork(h(t), t, \theta)$时, 则有迭代公式为
那么, 损失的梯度可以表示为
当然,此处可以使用其他数值解法,如RK2, RK4等等,但是存在以下问题, 如果时间步数很多,则会产生内存问题;此外,由于数值错误或者不稳定性甚至是求解器本身的不可微性,会导致反向传播无法进行。
伴随敏感度方法:
define $z(t+ \epsilon) = \int ^{t+\epsilon}_t f(z(t), t, \theta)dt + z(t) = T_\epsilon(z(t), t)$, and $a(t) = \frac{dL}{dZ(t)}$
we can get
下面证明 $\frac{da(t)}{dt}= -a(t)^T \frac{df(z(t), t, \theta)}{dz}$
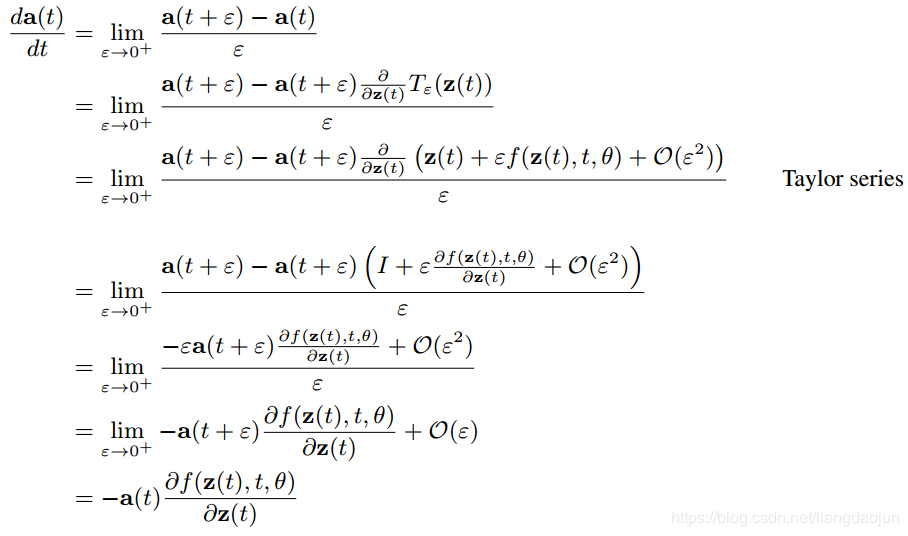
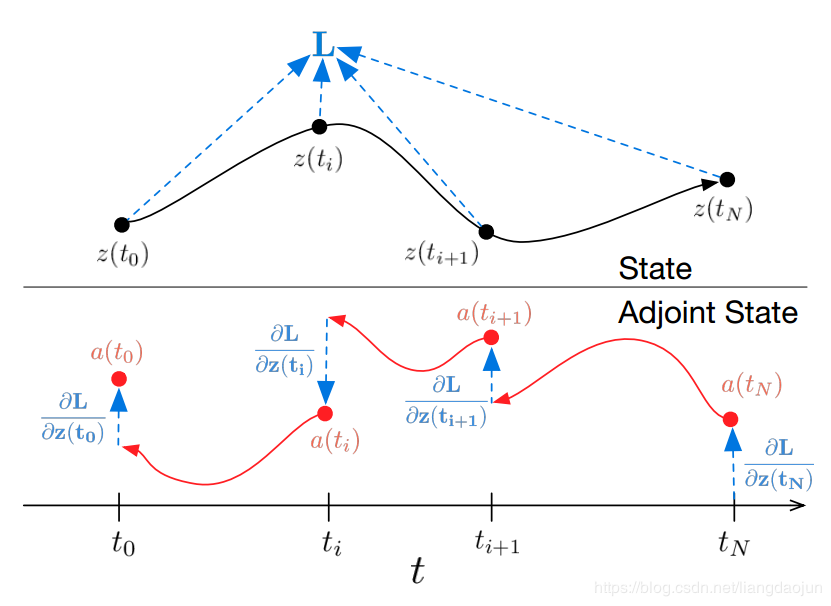
因此,整体前向和反向传播网络如下图所示:
下面讨论损失函数对于$\theta$的梯度,和上述几乎同样的推导过程。
整体推导过程:
其中 $a_{\theta}(t):=\frac{dL}{d\theta(t)}, a_t(t):=\frac{dL}{dt(t)}$
f函数的雅可比矩阵为
则类似上述推导可以得出对应的伴随敏感状态为
FASTER ODE ADJOINTS WITH 12 LINES OF CODE
类似于event_triggered MPC的思想,满足一定条件时不进行计算,不满足时才进行计算, code
对于下述广义形式的ODE问题:
假设$\hat y(t)$表示对应时刻的估计值,一旦有估计值,可以继续进行计算得到 $\hat y_{candidate}(t+\Delta)$, 此外, $y_{err}\in R^d$表示进行此步计算后,每个channel的numerical error。则对于给定的绝对容忍度$\text{ATOL}$(一般$1e-9$)和相对误差容忍度,以及对应的norm(比如$||y||=\sqrt{\frac{1}{d}\sum^d_{i=1}y_i^2}$),则定义
其中$\text{max}$是按每个channel来取的,则对应的误差率为 $\text{error ratio}$
如果$r<1$,则认为这个误差是可以被接受的,不需要重新计算,直接令 $\hat y(t+\Delta) = \hat y_{candidate}(t+\Delta)$;反之,则认为上述的误差太大,选取更小的$\Delta$并进行测试。
Deep Equilibrium Models
整体思想是权重共享,然后将输入不断得给到一个layer中去,假设最终收敛,称之为不动点。
Back propagation: $(.)$代表$f_{\theta}(z_{1:T}^*;x_{1:T})$中的参数(比如$\theta, x_{1:T}$)
因此可得
令 $g_{\theta}(z_{1:T}^\star)=f_{\theta}(z^\star_{1:T};x_{1:T})-z_{1:T}^\star$ ,可得
对于不动点进行估计的有效方法
并采用拟牛顿法中的Broyden方法对于雅可比矩阵的逆进行近似
其中$\Delta z^{[i+1]} = z_{1:T}^{[i+1]}-z_{1:T}^{[i]}$, $\Delta g_{\theta}^{[i+1]} = g_{\theta}(z_{1:T}^{[i+1]};x_{1:T}) - g_{\theta}(z_{1:T}^{[i]};x_{1:T})$,初始$g_{\theta}$可以设置为0.
另一种方案是back propagation直接计算 $-\frac{\partial l}{\partial z_{1:T}^\star}J^{-1}_{g_{\theta}}\big|_{z_{1:T}^\star}$
然后用拟牛顿法来解这个问题
ODE2VAE
对于下述问题:
可以等价变为两个一阶ode的形式
即
其中$W=\{W_l\}_{l=1}^L$,表示L层中所有的权重和偏差参数,假设对$p(W)$进行一个先验的假设,则对此进行采样,就会确定一个神经网络,从而决定ODE的轨迹
二阶ODE流模型
对于上述的ODE模型,根据Neural ODE中的结果,可知
从而可知
ODE2VAE模型
infer在低维空间上的速度和位置轨迹,但是仍然能将数据拟合的很好。下面假设动态方程:
下面给出变分推断基本假设
ELBO
其中,先验分布 $p(W,z_0)$是标准高斯分布。
文章对于损失函数的改进,
- 提出问题
- VAE模型优化ELBO不一定得到正确的inference。
- KL项和重构项存在不平衡的矛盾。——->加权
- 在此问题中,encoder只是为了得到最初的$z_0$,对于长时预测问题或在小数据或初始数据分布和数据分布不一致时,(26)中动态损失项(第三项),很容易支配VAE的损失,引起欠拟合———-> 减少编码器分布和ODE流分布之间的距离
- 方案:
- 对于$-KL(q(W)||p(W))$,增加一个权重$\beta=|q|/|W|$,表示因空间维度和权重数目的比。
- 减少编码器分布和ODE流分布之间的距离
- 提出问题
FFJORD: free form continuous dynamics for scalable reversible generative models
对于CNF,根据neural ode 中有
因此,对于增广状态有,
根据下述重要推论中的第二条,可知
How to train your Neural ODE
对于一般的ODE,积分步长相当于堆叠了很多层的layer,本篇文章引入了正则化来缓解这种问题。最终达到用更简单的动力学方程有更快的收敛速度,仅需要更少的离散化步骤求解。 Neural ODE 可以节省内存开销,但需要很长的时间训练。
为什么需要正则化?从下述图中可看出,两模型输入输出相同,但右图中局部特性不理想,比如局部轨迹变化大,速度不均匀等。左图更加规则。
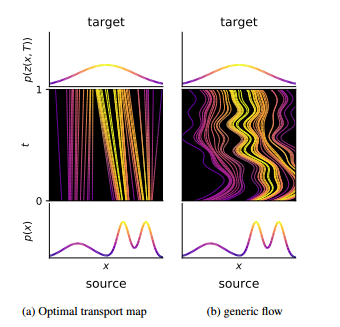
如何measure vector field是否“规则”? 评估在各点$z(t)$所受的“力”,也就是
因此,引入两个正则化项:一个是为了对f正则化,另一个则是对$\nabla f$正则化
- 评估流f行走的距离,也可认为是流模型的动能。
- 对于vector field中的雅可比行列式进行正则化
采用Optimal Transport问题中的Benamou-Brenier方法,引入惩罚项
首先,介绍Optimal Transport, 假设有两个分布 $p(x), q(x)$,及映射 $z:p(x)->q(z)$,则应最小化传输代价
如果将映射$z(x,T)$写为通过ODE函数f得到的一个映射,则可转化为
此式是(32)式的上界,只有当在最优的时候才会和(32)相等,而后,为了保证$\rho_T(z)=q$,引入KL散度,且恰好可以简化成以下形式($\rho_0 = p_{\theta}$)
此时(33)变为
第一项即为添加的正则项
可发现即使f正则化到很小,如果雅可比矩阵很大,那么(31)依然很大,因此,引入雅可比矩阵的F范数来进行正则化
最终算法实现

