PaperList For Dynamic systems with DNN
TS prediction
Dynamic Systems for Deep Learning
本文将从动力学系统角度去理解深度神经网络。
Flow based Models
本节将会介绍生成模型中非常典型的一类方法,流模型 。
概率图模型
Yading: fast clustering of large-scale time series data
概述
包括三个步骤:
- (1)从数据集中采样;
- (2)在采样的数据集上面进行聚类算法;
- (3)将数据集中其他的数据根据采样数据集的类别进行分类
现在的聚类算法可以大致分为两类:根据相似性度量是否是直接用在输入的数据集上的还是用在从数据集中提取的特征上的
- 第一类: Golay et al 研究了三种时间序列的相似性度量,欧氏距离,两个基于互相关性的距离; Liao et all 采用DTW(Dynamic Time Warping)动态时间弯曲和遗传聚类来对时间序列进行分类
- 第二类:是基于时间序列是根据内在的模型和概率分布的假设来进行聚类的。比如ARMA(Auto-Aggressive Integrated Moving Average)算法,高斯混合算法,缺点是是模型的学习的计算复杂度很高
相似性度量:
(1)Lp范数: 其中L1范数对于冲击噪声是鲁棒的;但是对于$p\geq 3$来说会遇到维数灾问题
(2)Pearson’s correlation:取值范围是[-1,1],两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:
上式是总体皮尔逊相关系数,下面是样本皮尔逊相关系数,一般用r表示:
(3)DTW(动态时间弯曲距离):

Data Reduction:分为降维或者减少时间序列的数量(size)
离散傅里叶变换(DFT)用于在频域中表示时间序列;离散小波变换用于提供额外的信息;奇异值分解(SVD)和分段聚合近似(PAA)

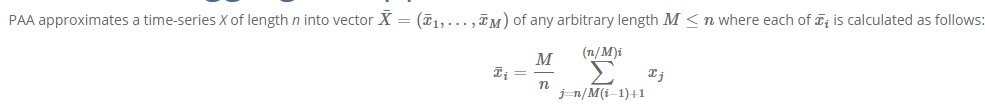
采样可以减少时间序列数据集的大小:随机采样/有偏采样